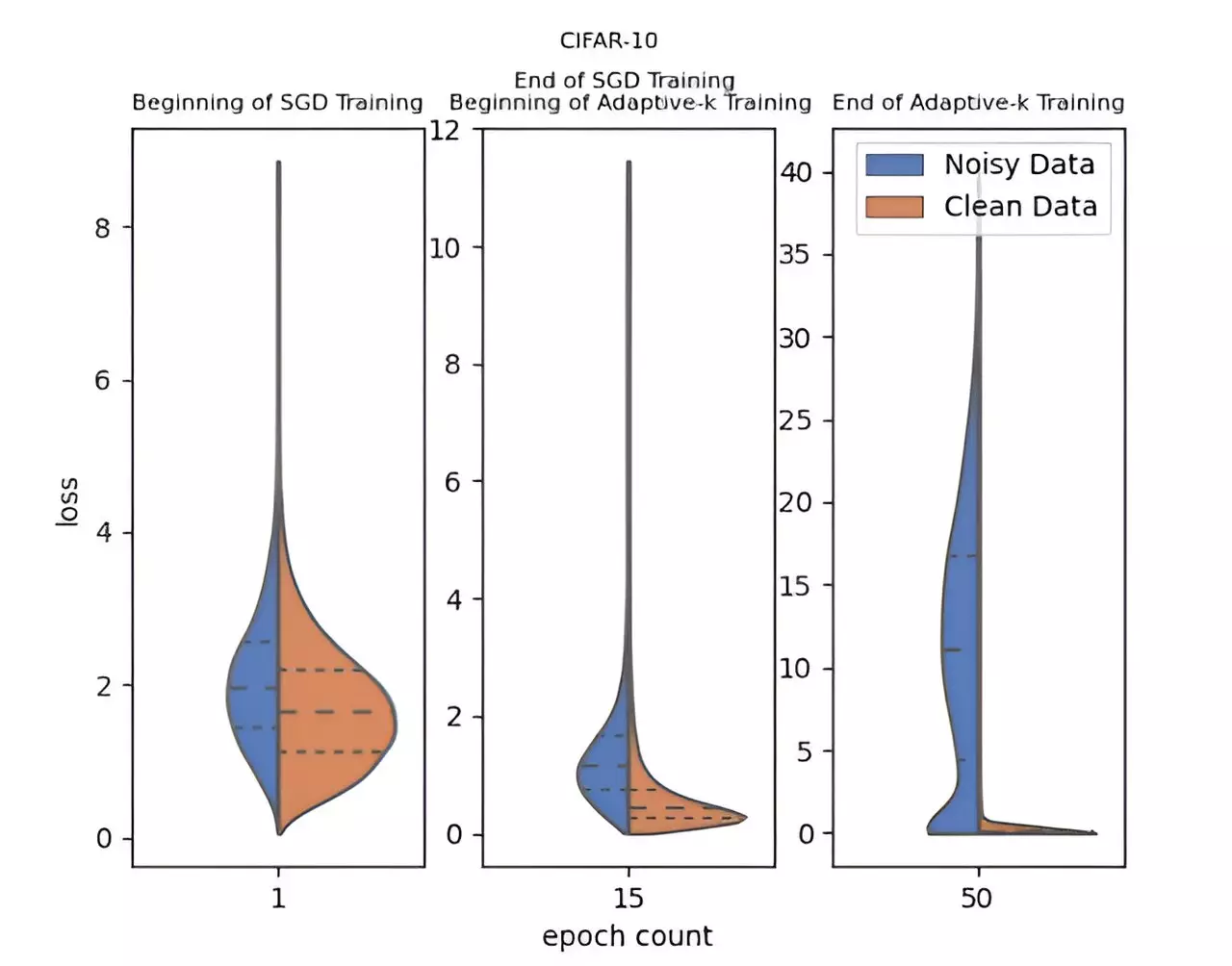
In the realm of deep learning, the effectiveness of models largely hinges on the quality of the datasets used for training. Unfortunately, datasets often come fraught with label noise, which can severely impair the models’ ability to generalize well on unseen data. Label noise can arise due to human error during data labeling or inconsistencies in data collection methods, thereby skewing the learning process of the model. Recognizing this challenge, a dedicated team of researchers from Yildiz Technical University embarked on a mission to devise a solution that improves model robustness in noisy environments.
The culmination of their effort led to the development of a novel algorithm known as Adaptive-k. This innovative method stands out by adaptively determining the number of samples selected from a mini-batch for model updating. Unlike traditional training methods that often treat all samples equally, Adaptive-k enables a better discernment of noisy samples, enhancing the training performance on datasets riddled with label noise. Its simplicity and effectiveness lie in the fact that it does not necessitate prior knowledge of the noise levels present in the dataset, nor does it require additional model training or an extension of training time.
The Adaptive-k algorithm has undergone rigorous testing against various popular algorithms, including Vanilla, MKL, Vanilla-MKL, and Trimloss. In these empirical studies, the research team assessed its performance relative to an idealized Oracle scenario—where noisy samples are perfectly identified and excluded. The results were remarkable: Adaptive-k consistently outperformed its peers across diverse datasets, including three image sets and four text sets. This not only validates its robust methodology but also signifies a potential paradigm shift in deep learning training strategies aimed at tackling label noise.
Another compelling aspect of Adaptive-k is its versatility; it is compatible with a variety of optimization algorithms, including but not limited to Stochastic Gradient Descent (SGD), Stochastic Gradient Descent with Momentum (SGDM), and Adam. This adaptability opens up numerous avenues for its application across various deep learning frameworks and use cases, thereby increasing its potential impact on the field.
Moreover, the research team points to several future directions for their work. They plan to refine the Adaptive-k method further, exploring additional applications and striving to enhance its performance metrics. The intent is clear: to deepen our understanding of how this method can be improved while maintaining its ease of use and broad applicability.
The Adaptive-k method marks a significant advance in the fight against label noise in deep learning. With its strong performance, simplicity, and adaptability, it positions itself as a game-changer for researchers and practitioners alike. As the field continues to evolve, Adaptive-k offers a promising pathway for not only improving training processes but also for fostering deeper insights into the complexities of noisy datasets in machine learning.