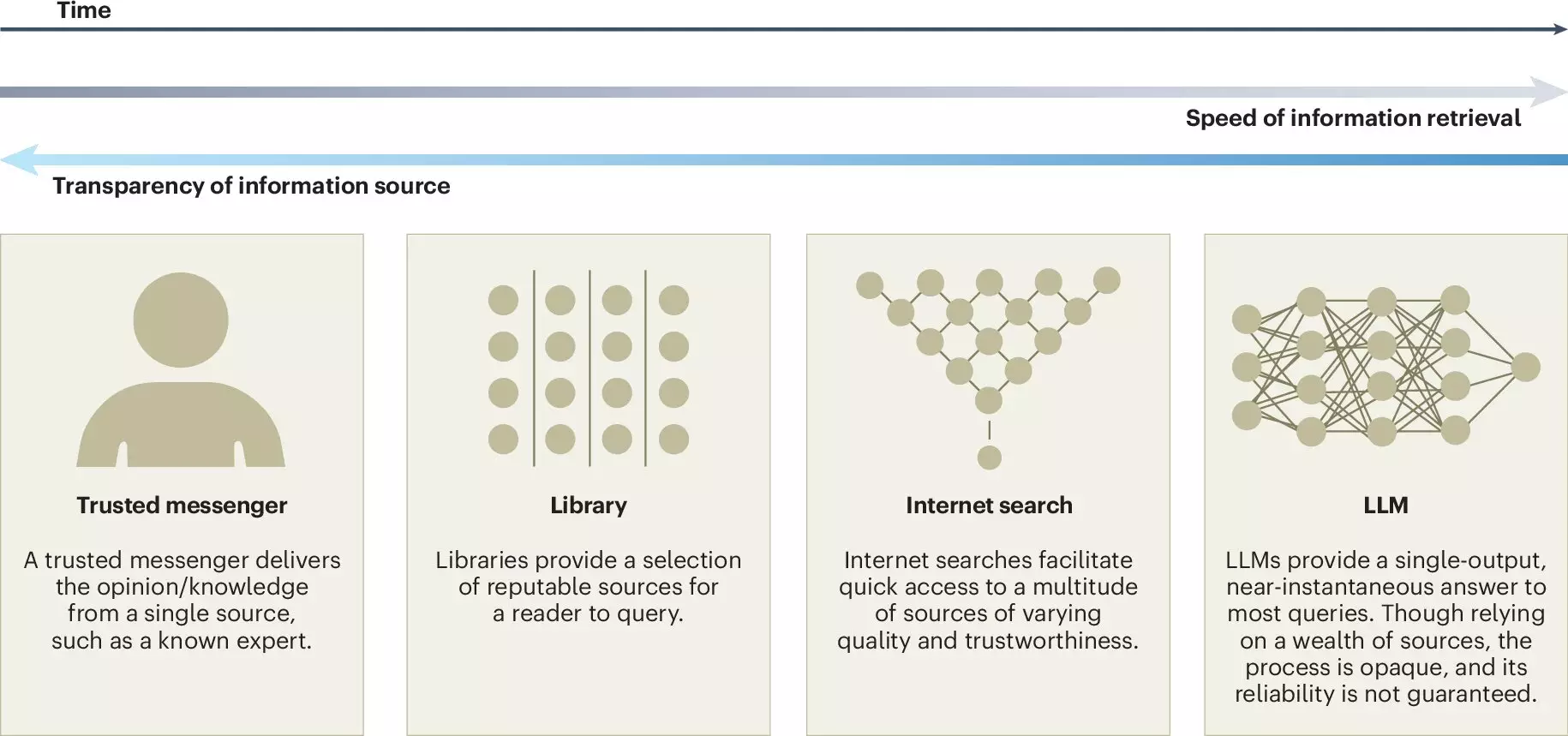
In the digital age, large language models (LLMs) have emerged as transformative tools within various sectors of society. Their ability to process and generate human-like text is reshaping our interaction with technology, information dissemination, and decision-making processes. As LLMs, such as OpenAI’s ChatGPT, become embedded in daily activities—from drafting emails to researching topics—understanding their implications for collective intelligence is crucial. A recent study published in *Nature Human Behaviour* by a group of interdisciplinary researchers sheds light on the nuanced opportunities and challenges posed by LLMs, particularly their impact on collaborative efforts within groups and organizations.
Collective intelligence can be defined as the enhanced capacity that emerges from the collaboration and competition of many individuals. This phenomenon manifests in myriad forms, ranging from small, focused groups within corporate environments to vast, decentralized communities found in platforms like Wikipedia. It is grounded in the premise that combining diverse expertise and perspectives often yields superior solutions compared to singular, isolated efforts. In a world increasingly reliant on specialized knowledge, harnessing collective intelligence becomes imperative for effective problem-solving and informed decision-making.
The potential of LLMs to bolster collective intelligence is multifaceted. One of the primary advantages highlighted by researchers is the role of LLMs in democratizing access to knowledge. By providing real-time translation services and facilitating clear communication, LLMs break down language barriers, thereby fostering inclusivity in discussions. Moreover, their capability to distill large volumes of data into digestible insights can significantly enhance the idea-generation process, enabling teams to quickly synthesize diverse opinions and reach consensus more efficiently.
Additionally, LLMs can serve as repositories of knowledge, summarizing ongoing debates or presenting historical context that may not be readily available to all participants. This characteristic is invaluable for ensuring comprehensive discussions on complex topics, where maintaining an informed collective consciousness is essential.
Despite their potential advantages, the risks posed by LLMs cannot be underestimated. One significant concern is the possible erosion of intrinsic motivation among individuals contributing to collective knowledge. As reliance on AI models grows, there is a risk that user-generated contributions to platforms like Wikipedia or Stack Overflow could diminish, leading to a homogenization of information sources. The diversity of viewpoints enriched through human participation may be replaced by a more uniform output generated by LLMs, potentially leading to a diluted intellectual landscape.
Furthermore, the phenomenon of false consensus presents another layer of complexity. The data used to train these models predominantly reflects the majority perspectives available online, which raises concerns about the representation of minority views. Such biases can create a misleading perception of popular agreement on contentious issues, thereby silencing dissent and fostering pluralistic ignorance. It is essential to uncover how these dynamics could impact societal norms and discourse.
The authors of the study advocate for a proactive approach in the development and implementation of LLMs. This includes calls for increased transparency regarding the data utilized in training such models, as well as the implementation of independent audits to scrutinize the ethical ramifications and biases inherent in their algorithms. By doing so, stakeholders can gain deeper insights into the processing and dissemination of information and mitigate potential adverse effects on collective intelligence.
Additionally, the research team emphasizes the importance of human involvement in the LLM training process, specifically in achieving diverse representation within datasets. Addressing this issue is vital for fostering more equitable dialogue and ensuring the robustness of collective intelligence against homogenization.
As LLM technology continues to evolve, the implications for collective intelligence must be at the forefront of discussions among researchers, policymakers, and developers. The nuanced relationship between LLMs and collective intelligence necessitates careful consideration of how these technologies can be employed responsibly to enhance human collaboration rather than hinder it. By acknowledging both the capabilities and limitations of LLMs, society can aim to harness their potential for the greater good, ensuring that the richness of human thought remains central in a rapidly changing information landscape. This balanced approach will be pivotal for sustaining the integrity of collective intelligence moving forward.